Why China's AI Regulatory Model Is Different
Most Western summaries describe China as if it has a single AI statute waiting to be compared with the EU AI Act. That's wrong. China already regulates AI through a stack of binding instruments that attach to specific service types and risk patterns. The practical center of gravity is public-facing online services, recommendation engines, synthetic media, and generative AI made available to users in China. That structure matters because compliance starts with service classification, not with a generic policy statement.
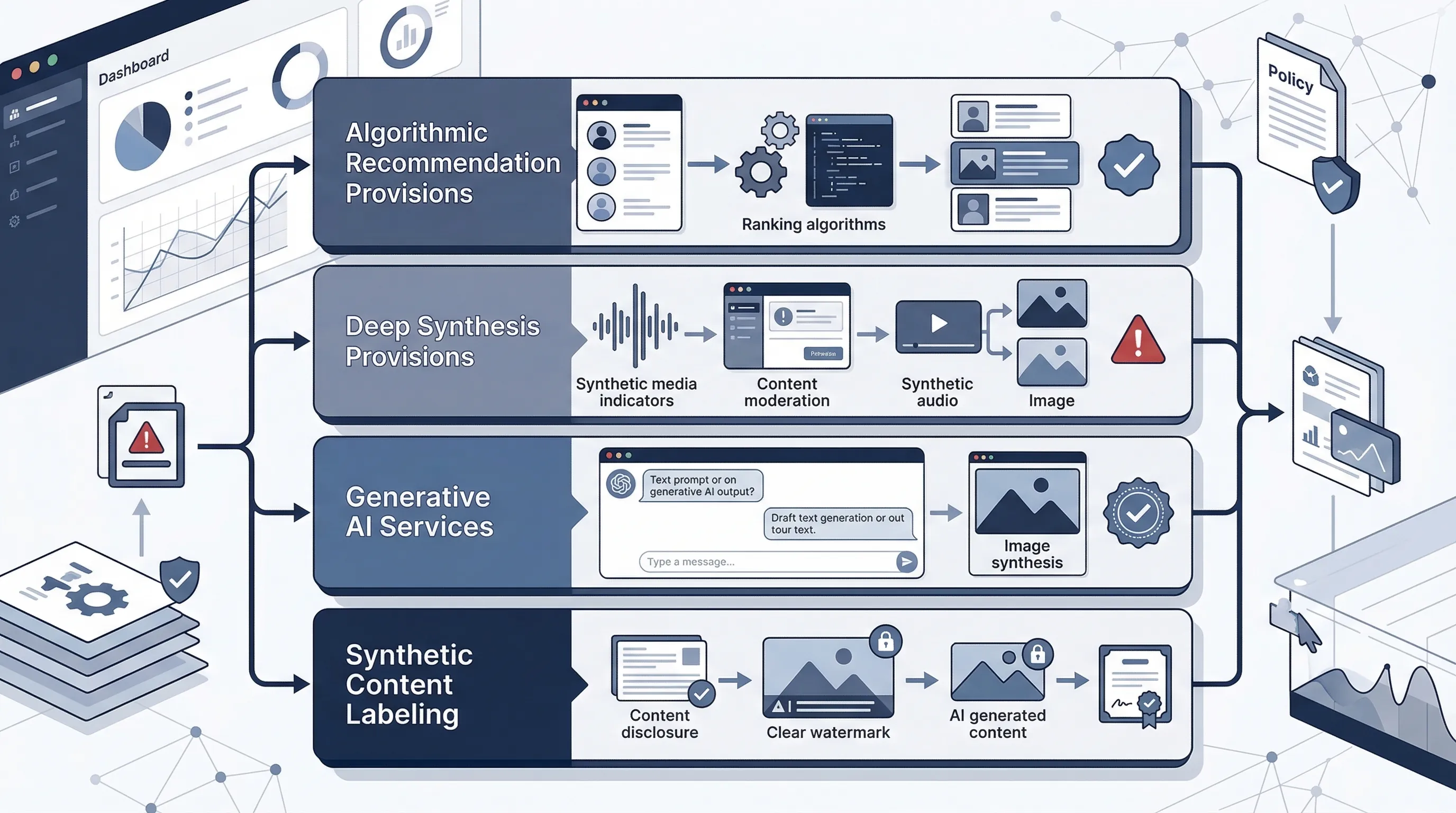
The four core instruments are now stable enough to treat as the base operational stack. The Algorithmic Recommendation Provisions took effect on 1 March 2022. The Deep Synthesis Provisions took effect on 10 January 2023. The Interim Measures for Generative AI Services took effect on 15 August 2023. The Measures for Labeling AI-Generated and Synthetic Content were issued in March 2025, take effect on September 1, 2025, and add explicit and implicit labeling obligations for AI-generated and synthetic content in relevant scenarios. Together, they form one of the most operational AI rule environments in the world. For the underlying official texts, see the algorithm rules, deep synthesis rules, GenAI measures notice, and the 2025 labeling measures.
The logic of the Chinese model is also different from the EU model. China is less focused on a single abstract risk taxonomy and more focused on provider responsibility, content governance, filing and assessment triggers, user transparency, and misuse prevention in live internet services. That doesn't make it lighter. In many practical cases it makes it more immediate, because obligations attach to actual service behavior rather than to a long theoretical classification exercise.
That difference is why imported governance templates often fail in China. A generic responsible-AI policy can look polished and still be commercially useless if it doesn't tell the product team when labeling is required, when user controls must be visible, what records must exist, and when a provider may trigger filing or security-assessment expectations. China's regime is operational. Your compliance approach has to be operational too.
Official source links: Algorithmic Recommendation Provisions · Deep Synthesis Provisions · Interim Measures for Generative AI Services · 2025 labeling measures
Need a structured assessment workflow? The AI Controls Starter gives you the system inventory, gap analysis, and evidence tracker you need to classify China-facing AI services.
Run the free readiness assessment to see where your current controls break.
The Four-Rule Stack in Plain Language
Before you start mapping controls, get the vocabulary right. These four instruments overlap, but they don't do the same job. If your internal teams can't distinguish them, they'll either over-control everything or miss the triggering rule entirely.
- Algorithmic recommendation
- Rules for recommendation, ranking, filtering, retrieval, dispatching, and similar algorithmic functions used in internet information services.
- Deep synthesis
- Rules for generating, editing, or manipulating text, image, audio, video, or virtual scenes in ways that create synthetic or altered content.
- Generative AI services
- Rules for generative AI services made available to the public in China, including provider responsibility for lawful content and service governance.
- Synthetic-content labeling
- Rules for marking or labeling AI-generated and synthetic content so users, platforms, and counterparties can identify that content appropriately.
A single product can fall under more than one of these categories. A public chatbot that recommends content, generates responses, and returns synthetic images can trigger all four layers depending on how it operates. That's why the first compliance task in China is not policy drafting. It's service decomposition. You break the product into its actual AI-enabled functions and then determine which rule layer attaches to which function.
| Instrument | Effective date | Main trigger | Main operational focus |
|---|---|---|---|
| Algorithmic Recommendation Provisions | 1 Mar 2022 | Recommendation, ranking, filtering, dispatching, search logic | User transparency, user controls, records, filing, manipulation restrictions |
| Deep Synthesis Provisions | 10 Jan 2023 | Synthetic generation or manipulation of media/content | Security management, marking, identity checks, misuse prevention |
| Interim GenAI Measures | 15 Aug 2023 | Public-facing generative AI services | Provider responsibility, lawful content, data governance, complaint handling |
| Synthetic Content Labeling Measures | 7 Mar 2025 | AI-generated or synthetic content distribution | Labeling, disclosure, workflow ownership, content-handling controls |
Regulation 1 - Algorithmic Recommendation Provisions
This is the foundational layer for internet information services that rely on algorithmic recommendation logic. The scope is wider than many companies first assume. It isn't limited to social feeds. The rule expressly covers recommendation, personalized delivery, ranking, search filtering, and dispatching or decision-style functions used to provide online information services. If your product decides what a user sees, in what order they see it, or how they are routed, this rule can be relevant.
The compliance burden sits in three places. First, transparency and user rights: users must be informed that algorithmic recommendation is being used, and qualifying services must provide meaningful user controls, including options that reduce personalization and functions for managing user labels in relevant contexts. Second, provider governance: providers are expected to establish internal controls covering algorithmic security, data security, personal information protection, review mechanisms, and incident handling. Third, filing and safety obligations: services with public-opinion or social-mobilization characteristics can trigger filing and security-assessment expectations.
From an SME perspective, the operational question is simple: where in the product are you using algorithmic selection or dispatch? Then ask what evidence exists. Can you show users what is personalized? Can they turn it off where required? Do you log how recommendation logic is governed? Do you have documented rules for labels, appeal, and abnormal behavior? If the answer is no, your legal position is weak no matter how good your ethics statement sounds.
| Obligation | Who it applies to | Operational evidence |
|---|---|---|
| User notification of algorithmic recommendation | Public-facing internet information services using recommendation logic | UI disclosure, help-center language, product screenshots, release record |
| User controls and label management | Services personalizing content or outputs around user characteristics | User settings page, feature spec, test evidence, support procedures |
| Algorithm governance and review | All in-scope providers | Policy, RACI, review log, incident workflow, data protection controls |
| Filing / public-opinion sensitivity analysis | Higher-impact providers with qualifying service attributes | Legal assessment memo, classification worksheet, filing record where applicable |
Regulation 2 - Deep Synthesis Provisions
Deep synthesis rules address a different risk profile: AI systems that generate or manipulate content in ways that can create synthetic or deceptive media. This includes text, image, audio, video, and virtual scene generation or modification. In practical terms, if your service produces avatars, voice cloning, face swaps, image edits, video generation, or other synthetic media outputs, this layer matters.
The core control logic is not subtle. China expects providers to manage misuse risk at source. That means governance over service access, identity-related controls in relevant use cases, content marking, operational safeguards, complaint handling, and procedures for preventing or stopping misuse. The rule is aimed squarely at impersonation, fraud, deception, and social harm. If your product team says "we just provide the tool," that position is structurally weak under this model. Provider responsibility sits much closer to the actual product than many global SaaS teams are used to.
For most SMEs, the right response isn't to overbuild a giant trust-and-safety organization. It's to define the specific deep-synthesis risks in your workflow and assign controls to named owners. Who approves identity-sensitive use cases? How do users report impersonation or harmful manipulation? What content marking exists? What records are retained? What happens when a malicious use pattern appears? Those are governance questions, not just engineering questions.
| Deep synthesis risk | Required control | Evidence artifact |
|---|---|---|
| Impersonation or misleading synthetic media | Output marking, use-case restriction, escalation path | Product rules, moderation SOP, sample marked outputs |
| Identity-sensitive service misuse | Account controls, identity verification where relevant, abuse review | Access control design, onboarding checks, incident log |
| Unsafe or harmful generation patterns | Prompt restrictions, moderation filters, complaint handling | Policy, filter rules, enforcement record, user reporting workflow |
| Weak provider accountability | Named service owner, legal owner, trust-and-safety owner | RACI matrix, management review note, vendor oversight record |
Regulation 3 - Interim Measures for Generative AI Services
The Interim Measures for Generative AI Services are the rule most foreign teams know by name, and the one they most often misunderstand. The reason is simple: the Measures are not a stand-alone compliance universe. They sit on top of the earlier rule stack and focus on generative AI services made available to the public. If your use case is public-facing, customer-facing, or platform-facing inside China, you should assume this layer is relevant until proven otherwise.
The rule's practical emphasis is provider responsibility. Providers are expected to manage lawful content, service rules, complaint handling, data and input governance, and service safety. That doesn't mean every internal enterprise AI workflow is treated the same as a public chatbot. It does mean that once a generative service is exposed to the public, governance expectations tighten quickly. A private internal assistant used by a narrow operations team is not the same exposure profile as a public assistant embedded on a consumer platform.
For commercial teams, the biggest mistake is failing to distinguish between model risk and service risk. You can buy a third-party model and still be the party exposed on the service side. If your company controls the user interface, customer journey, complaint flow, output rules, or API wrapper, then "the model vendor handles safety" is not enough. China cares about the service that reaches the user.
The right implementation move is to document the service architecture from user prompt to output delivery. Identify which party owns moderation, which party owns record retention, which party owns labeling, which party owns complaints, and which party owns changes to the upstream model. If those owners don't exist, your compliance posture is mostly fictional.
| Requirement theme | Product / legal owner | Implementation action |
|---|---|---|
| Lawful output and content controls | Product + legal + trust and safety | Document acceptable use, moderation logic, escalation criteria, and enforcement |
| Data and input governance | Data owner + privacy owner | Classify training and prompt inputs, restrict sensitive data flows, log exceptions |
| User complaints and feedback handling | Customer operations + legal | Publish complaint route, response SLA, and remediation path |
| Third-party model or API governance | Procurement + engineering + compliance | Vendor assessment, contract review, change-log monitoring, fallback plan |
Common failure pattern: teams apply the GenAI Measures only to the model vendor and ignore the wrapper product, user journey, and complaint process they own themselves. That's a category error. The service layer is where many obligations land.
Regulation 4 - 2025 Synthetic Content Labeling Measures
The 2025 labeling measures matter because they close a gap many providers were treating as a product-choice issue rather than a compliance issue. China issued the Measures for Labeling AI-Generated and Synthetic Content in March 2025, with effect from September 1, 2025. They make labeling a clearer operational expectation for AI-generated and synthetic content in the Chinese environment, including explicit and implicit labeling obligations in relevant scenarios.
This doesn't mean one universal label format will solve the problem. It means your workflow needs a defined answer to five questions: what content is considered synthetic, when it must be labeled, where the label appears, who owns exceptions, and how evidence is retained. Those decisions belong in product and compliance controls, not in scattered Slack threads or engineering folklore.
This is also the point where China's rule stack starts to intersect directly with global synthetic-content governance work such as NIST AI 100-4. The concepts are different in origin, but the operating question is the same: how do you make synthetic content identifiable in ways that are practical, reviewable, and defensible? If you're already selling synthetic-media controls globally, China forces you to tighten the workflow and make the owner explicit. The formal Chinese source for this layer is the Measures for Labeling AI-Generated and Synthetic Content.
| Content type | Labeling expectation | Workflow owner |
|---|---|---|
| AI-generated image or video | Visible or system-level marking consistent with service design and distribution path | Product owner + media operations |
| Synthetic voice or avatar output | Disclosure and control over deceptive or impersonation-sensitive use cases | Trust and safety + legal |
| AI-generated text in public service flows | Disclosure where output nature and user context create material risk of confusion | Product owner + compliance |
| Third-party distributed synthetic content | Retention of handling rules, labeling logic, and escalation process | Platform operations + vendor manager |
China AI Compliance Operating Model for SMEs
Most SMEs do not need a giant China governance bureaucracy. They need a service-based operating model. The cleanest version has six domains, each with a named owner and a small evidence set. If you can't assign owners in under 30 minutes, your organization is not ready to claim China AI compliance.
- AI service inventory: List every China-facing AI-enabled service, component, model wrapper, and synthetic-content feature.
- Rule applicability classification: Map each service to the algorithm, deep synthesis, GenAI, and labeling layers that apply.
- Content and output governance: Define what outputs are restricted, what must be marked, and what must be escalated.
- User transparency and user controls: Document disclosures, settings, appeal routes, and complaint channels.
- Record retention and filing readiness: Maintain legal assessments, logs, service rules, and review records in one controlled location.
- Third-party model and API governance: Assess vendors, document service-layer ownership, and track upstream changes.
That model is enough to move an SME from vague awareness to a defensible baseline. It also maps cleanly to ISO 42001 if you want a management-system backbone. China's rules tell you where the immediate product obligations sit. ISO 42001 gives you the machinery for ownership, review, corrective action, and documented information. Use both. Don't pretend one replaces the other.
Commercially sane move: build the China rule classification into the same inventory you already use for ISO 42001, NIST AI RMF, and customer due diligence. That keeps your evidence stack unified instead of multiplying spreadsheets across teams.
See how AI Controls Professional packages the cross-framework workflow.
China vs EU AI Act - Structural Differences
Don't force a false one-to-one comparison. The EU AI Act is a single risk-based regulation with operator roles, prohibited practices, and a high-risk architecture. China uses a rule stack built around online service behavior, content integrity, provider responsibility, and service-type triggers. The wrong comparison framework leads to the wrong implementation plan.
| Dimension | China AI stack | EU AI Act |
|---|---|---|
| Legal architecture | Multiple binding instruments | Single omnibus regulation |
| Primary trigger | Service behavior, content type, provider role, public-facing operation | Risk category, operator role, market placement, use case |
| Synthetic content focus | Strong and explicit | Present but structurally different |
| User controls | Embedded in service governance expectations | More role- and obligation-based by use case |
| Filing / assessment posture | Can be tied to public-opinion or higher-impact service characteristics | Conformity assessment for defined high-risk contexts |
| Suggested first implementation step | Service classification | Role and risk classification |
The commercial takeaway is blunt. If you sell into both China and the EU, don't run one global "AI law checklist" and expect it to work. Run two different entry points into one evidence system: China by service classification, EU by role and risk classification. The backend evidence can overlap. The front-end logic can't.
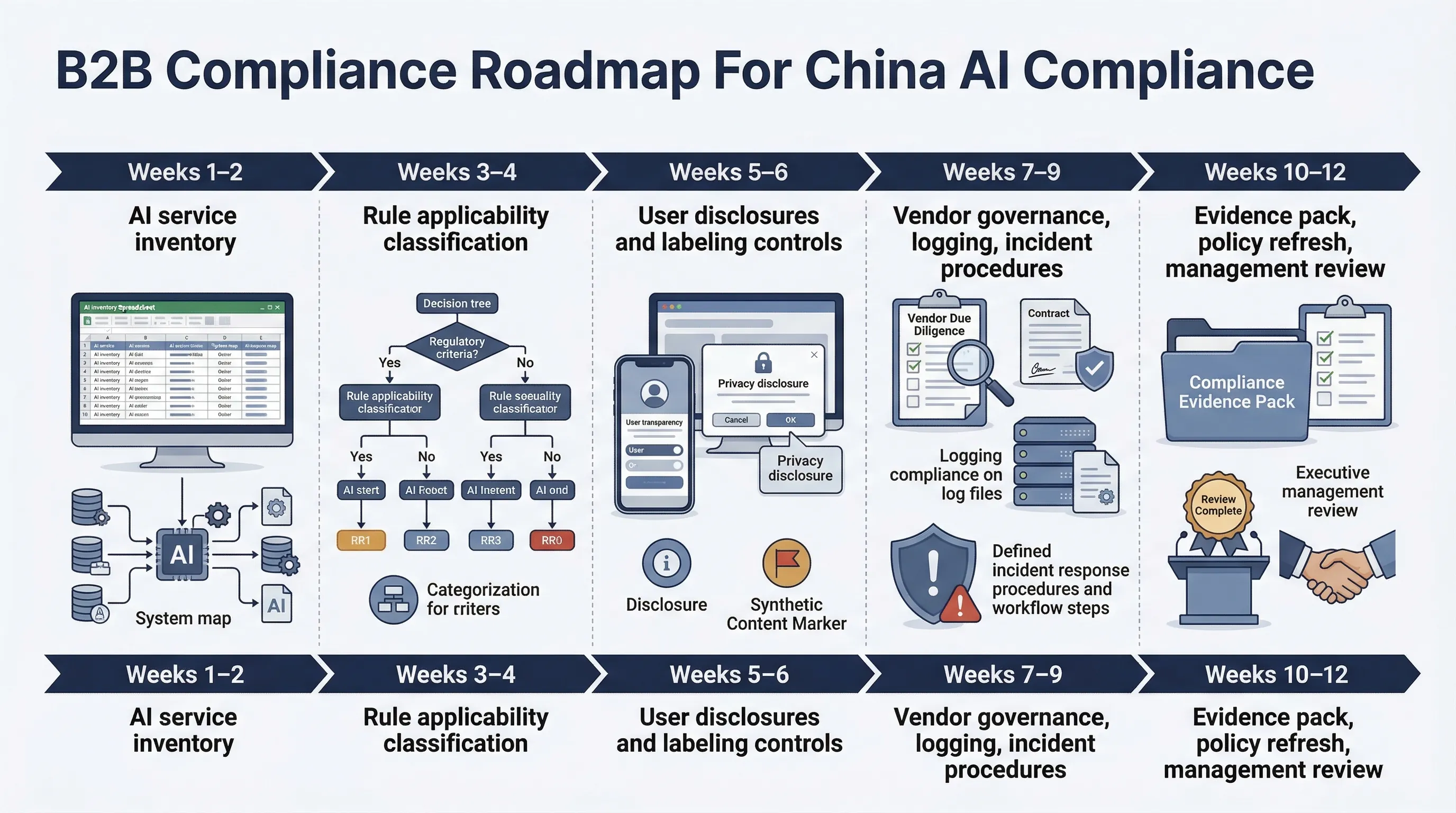
90-Day China AI Compliance Sprint
You don't need a 12-month theory exercise. You need a controlled sprint that produces decisions, owners, and records.
- Weeks 1-2: Inventory every China-facing AI-enabled service, recommendation function, synthetic-content flow, and third-party model dependency.
- Weeks 3-4: Classify each service against the four-rule stack and document why each rule does or does not apply.
- Weeks 5-6: Implement priority user disclosures, settings, complaint routes, and content-labeling controls.
- Weeks 7-9: Close third-party governance gaps, define record retention, and formalize trust-and-safety and legal escalation paths.
- Weeks 10-12: Run management review, test complaint handling, validate evidence completeness, and approve the operating baseline.
If you can't finish that in 90 days, the problem is usually not legal complexity. It's ownership failure. No named owner for the service inventory. No named owner for output labeling. No named owner for third-party model changes. Fix ownership first. The rest becomes manageable.
Need the templates, not just the theory? AI Controls Professional is the more useful package here. China compliance is document-and-owner heavy. You need service classification sheets, evidence logs, policy language, and operating procedures.
Compare AI Controls Starter and AI Controls Professional.