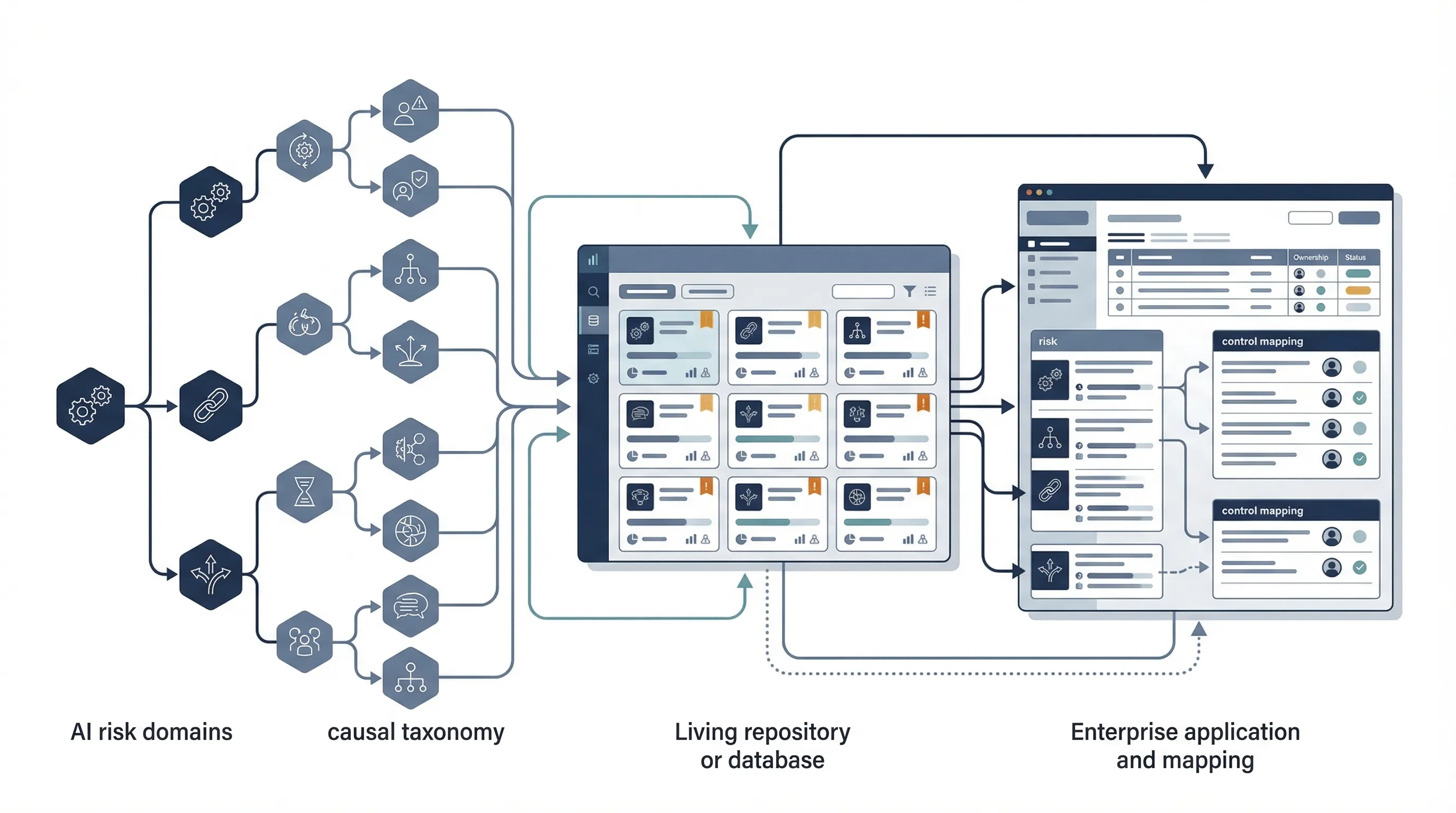
What the MIT AI Risk Repository Is
MIT describes the AI Risk Repository as a comprehensive living database of over 1700 AI risks categorized by their cause and risk domain. On the site, MIT says the repository has three parts: the AI Risk Database, the Causal Taxonomy of AI Risks, and the Domain Taxonomy of AI Risks. MIT also says the database captures 1700+ risks extracted from 74 existing frameworks and classifications, while the domain taxonomy classifies those risks into 7 domains and 24 subdomains. See the official repository site.
This matters because the repository does something most governance artifacts do not. It aggregates risk language across many frameworks into one searchable structure. That makes it useful as a risk-identification layer, especially for organizations that are still trying to build or clean up their internal risk register.
But the positioning has to stay precise. This is not a regulation. It is not a certifiable standard. It is not a complete control framework. It is a living risk database and taxonomy. If you market it as "MIT compliance," you will be wrong.
Official source links: MIT AI Risk Repository · database link on repository page · research report
Commercially useful framing: use the MIT repository as the upstream risk universe, then map those risks into your internal register, governance workflow, and control system. That is a much better use than treating it like a legal or audit endpoint.
The 7 Risk Domains and 24 Subdomains
MIT's Domain Taxonomy groups AI risks into seven domains. On the repository site these are: Discrimination & Toxicity, Privacy & Security, Misinformation, Malicious Actors, Human-Computer Interaction, Socioeconomic & Environmental, and AI System Safety, Failures, & Limitations. That domain structure is one of the most commercially useful parts of the repository because it gives teams a practical way to scope risk discussions without getting lost in hundreds of individual risk statements. See the official taxonomy page.
| Domain | What it captures | Example enterprise relevance |
|---|---|---|
| Discrimination & Toxicity | Fairness failures, misrepresentation, toxic content exposure, unequal performance | Hiring tools, customer service, content systems |
| Privacy & Security | Data leakage, sensitive inference, AI system vulnerabilities and attacks | LLM deployment, model APIs, internal copilots |
| Misinformation | False or misleading information and erosion of shared reality | GenAI products, search augmentation, knowledge tools |
| Malicious Actors | Fraud, scams, influence, surveillance, cyberattacks, weaponization | Identity abuse, impersonation, platform misuse |
| Human-Computer Interaction | Overreliance, unsafe use, loss of autonomy, problematic AI relationships | Copilots, decision support, companion systems |
| Socioeconomic & Environmental | Inequality, concentration of power, labor impacts, governance failure, environmental harm | Board oversight, strategic planning, policy posture |
| AI System Safety, Failures, & Limitations | Misalignment, dangerous capabilities, weak robustness, low transparency, multi-agent risk | Agentic AI, critical workflows, frontier-style scenarios |
The domain model is useful because it lets you begin broad and then go narrow. That is a better scoping method than starting immediately with dozens of disconnected "AI risks" from different documents.
How the Causal Taxonomy Works
The Causal Taxonomy is the part that makes the repository more than a list. MIT says it classifies how, when, and why an AI risk occurs. On the site, MIT breaks that into dimensions such as entity, intent, and timing. That gives organizations a way to analyze not only what the risk is, but where in the lifecycle and under what circumstances it emerges. See the official site.
| Causal dimension | Examples on MIT site | Why it matters |
|---|---|---|
| Entity | AI, human, or other | Helps separate system-originated failures from human misuse or ambiguous causes |
| Intent | Intentional, unintentional, or other | Helps distinguish harmful misuse from unintended failure or drift |
| Timing | Pre-deployment, post-deployment, or other | Helps place controls earlier or later in the lifecycle instead of treating all risks as operational incidents |
This is one of the strongest features for audit and control design. A risk register that includes causal dimensions becomes easier to map to controls, ownership, and testing points.
Common failure pattern: teams capture AI risks as a flat list with no lifecycle, intent, or origin logic. That makes prioritization worse and control mapping slower.
How Enterprises Can Use the Repository
MIT explicitly says industry can use the repository to conduct internal risk assessments, identify previously undocumented risks, evaluate risk exposure, develop mitigation strategies, and support research and training. That makes the commercial use case very clear. The repository is not just an academic artifact. It is a scoping and risk-identification tool for organizations. See the official use-case section.
| Enterprise use case | How to use the repository | Output |
|---|---|---|
| Internal risk assessment | Scan relevant domains and subdomains for system-specific exposure | AI risk register draft |
| Audit scoping | Use the domain and causal taxonomy to define review boundaries | Audit scope and criteria |
| Board education | Use the 7 domains to simplify the AI risk universe for leadership | board-focused risk landscape summary |
| Control gap analysis | Map identified risks into existing control families | Gap matrix and remediation plan |
| Training and awareness | Use domain examples and subdomains in education sessions | Risk-awareness material for staff |
The value is speed and breadth. You get a more complete risk universe faster than if you start from a blank spreadsheet.
MIT Repository vs NIST AI RMF vs ISO 42001
These serve different functions. The MIT repository helps identify and categorize risks. NIST AI RMF helps structure risk management. ISO 42001 helps institutionalize governance and evidence. Treating them as competitors is the wrong frame.
| Dimension | MIT Repository | NIST AI RMF | ISO 42001 |
|---|---|---|---|
| Primary job | Risk universe and taxonomy | Risk-management framework | Management-system governance |
| Primary use | Risk identification, scoping, audit framing | Mapping and managing AI risks | Ownership, documented information, review, continual improvement |
| Commercial role | Input layer | Method layer | Operating system layer |
How to Convert Repository Risks into a Risk Register
The repository becomes useful when translated into a working register. The basic sequence is straightforward. Select the relevant domains and subdomains, filter by causal factors where useful, pull the risks relevant to your use case, normalize duplicates, convert them into enterprise risk statements, assign owners, assess impact and likelihood, then map them to controls and evidence.
| Step | Action | Output |
|---|---|---|
| 1 | Select relevant domains/subdomains | Scoped risk universe |
| 2 | Apply causal filters where useful | Lifecycle-aware risk list |
| 3 | Normalize and rewrite risks into enterprise language | Draft internal risk statements |
| 4 | Assign owners and assess impact/likelihood | Prioritized risk register |
| 5 | Map risks to controls and evidence | Actionable governance and remediation plan |
That translation step is where most value is created. Without it, the repository stays educational rather than operational.
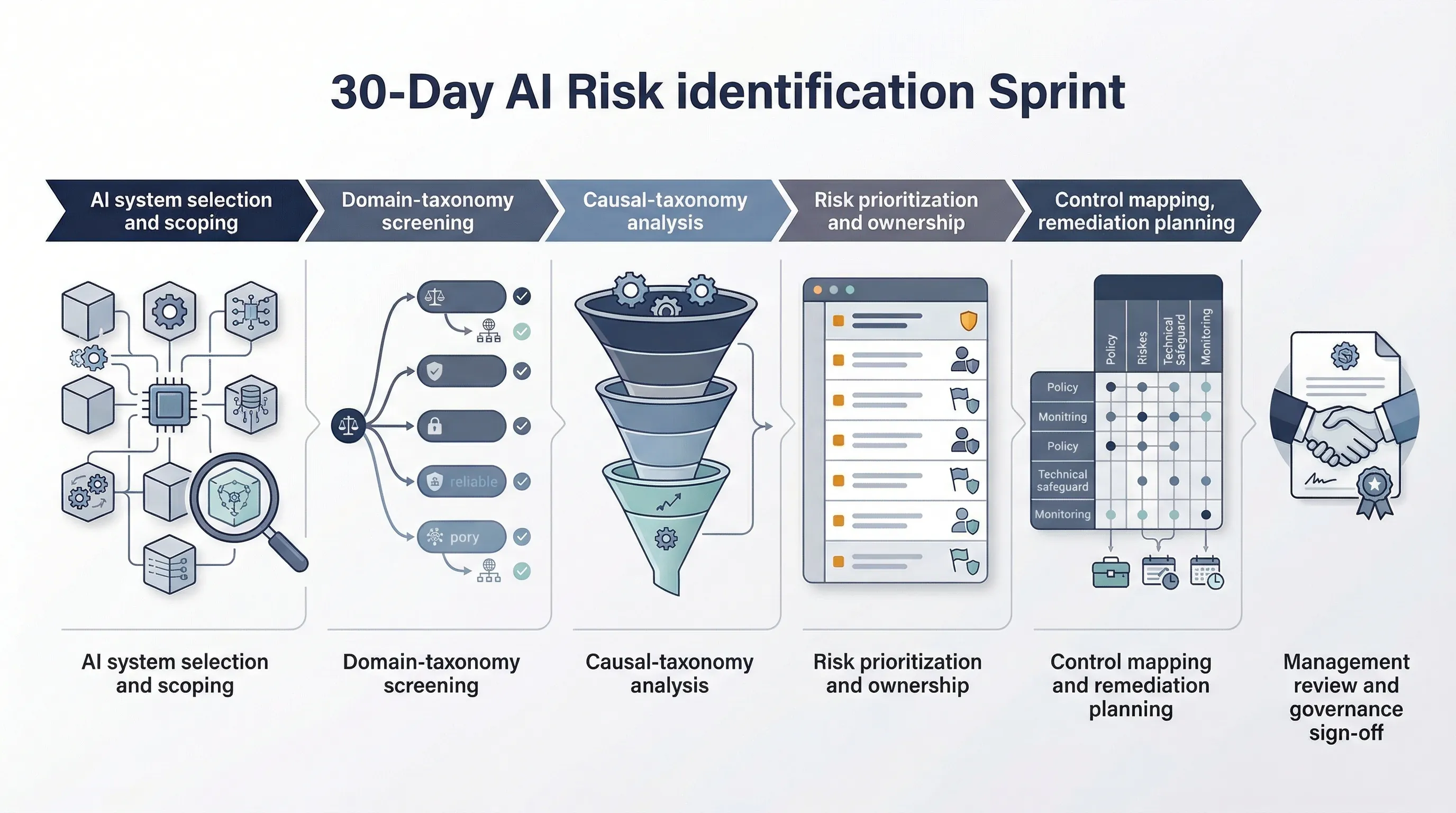
30-Day AI Risk Identification Sprint
You do not need a long research project to use the repository. You need a focused sprint.
- Week 1: pick priority AI systems and map them to the 7 MIT risk domains.
- Week 2: use causal filters to identify when, why, and how the key risks could emerge.
- Week 3: convert the resulting risk set into internal risk statements with owners.
- Week 4: map those risks to controls, evidence, and remediation priorities.
If you cannot do that in 30 days, the blocker is usually not taxonomy complexity. It is a lack of internal owner for risk translation.
Need the templates, not just the taxonomy? The MIT repository is excellent for risk identification, but it does not give you an evidence system. That is where AI Controls Professional becomes useful.
Compare AI Controls Starter and AI Controls Professional.