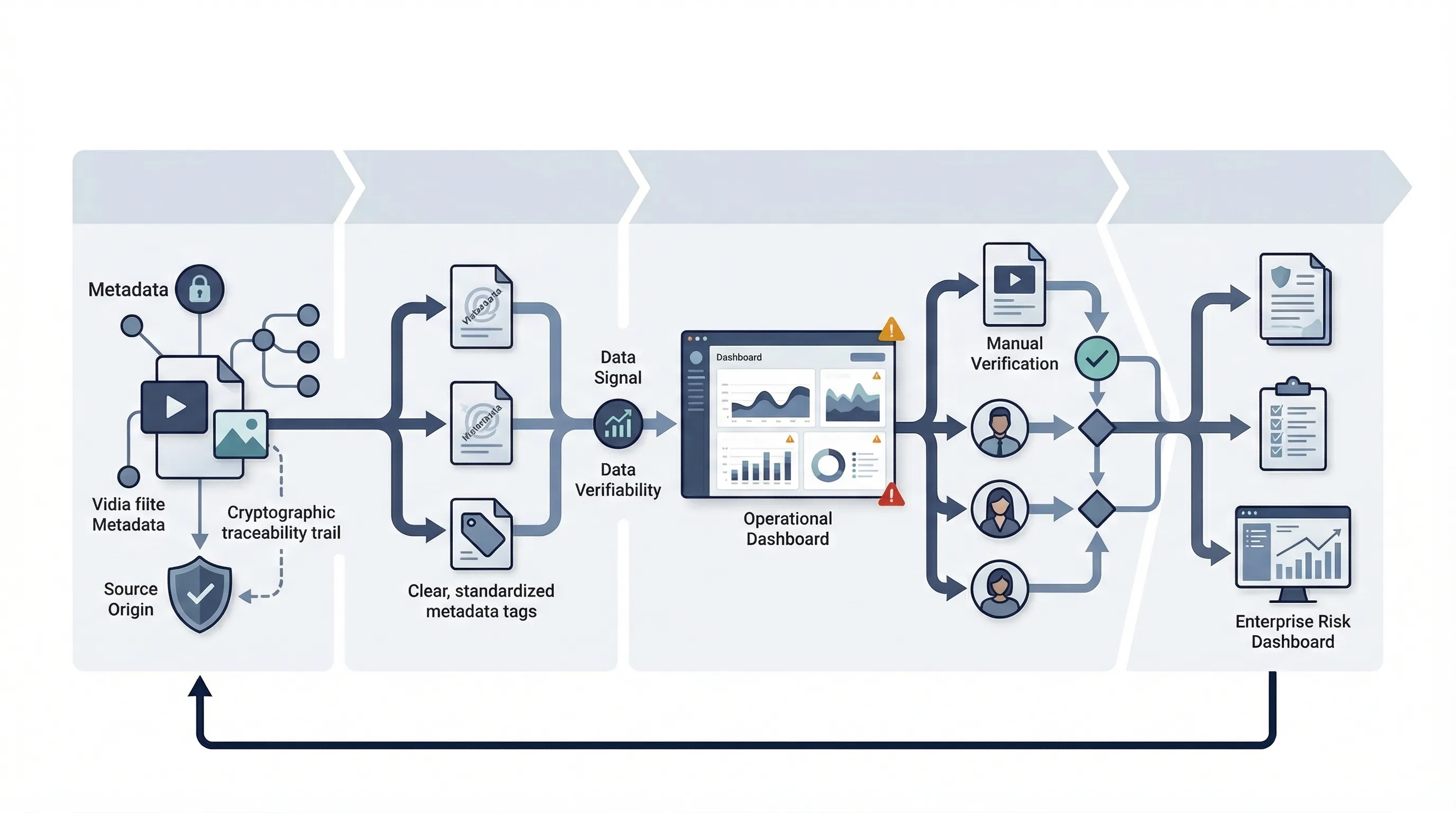
Why Synthetic Content Governance Matters
Synthetic content is no longer a niche research problem. It now lands directly in fraud, impersonation, misinformation, brand abuse, customer trust, and executive risk. The business question is not whether synthetic content exists. It is whether your organization can identify, label, govern, and respond to it without improvising every time something goes wrong.
NIST AI 100-4 is useful because it reframes the topic away from headline panic and toward practical controls. NIST's official publication page says the report examines existing standards, tools, methods, and practices for authenticating content and tracking provenance, labeling synthetic content, such as using watermarking, detecting synthetic content, preventing certain harmful outputs, testing software, and auditing and maintaining synthetic content. That is a governance stack, not a gadget list. See the official NIST publication page.
NIST published AI 100-4 on 20 November 2024. The publication is not law, but it is one of the stronger technical-governance reference points available for organizations trying to design synthetic content controls that are credible and reviewable. The official PDF is here: NIST AI 100-4 PDF.
Official source links: NIST publication page · official PDF · China 2025 labeling measures · EU AI-generated content labelling work
Commercially useful framing: NIST AI 100-4 should sit underneath your product policy, media workflow, and incident response model. It is most useful when translated into operating rules, not cited as a generic thought-leadership reference.
The NIST 100-4 Control Domains
A practical way to use AI 100-4 is to treat it as a control-domain map. NIST is explicit that synthetic-content governance is not one technical method. It spans provenance, labeling, detection, generation guardrails, testing, and ongoing maintenance. That is why organizations that obsess over watermarking alone usually fail. NIST itself does not present one silver bullet.
| Domain | What it is | Operational owner | Evidence |
|---|---|---|---|
| Provenance and authentication | Methods to establish where content came from and how it was created or modified | Product + media operations + security | Metadata rules, provenance records, chain-of-custody procedure |
| Labeling and watermarking | Visible or machine-readable signals that content is synthetic or AI-generated | Product owner + compliance | Labeling standard, UI evidence, metadata settings, policy language |
| Detection | Tools and methods for identifying likely synthetic content or manipulation | Trust and safety + security | Detection workflow, threshold logic, escalation records |
| Generation guardrails | Controls intended to reduce harmful or prohibited outputs at source | Model owner + product owner | Prompt restrictions, policy filters, red-team findings |
| Testing | Evaluation of transparency tools and controls before operational reliance | Security + QA + compliance | Test results, validation notes, performance reviews |
| Auditing and maintenance | Ongoing review, control upkeep, and adaptation to new failure patterns | Governance owner + internal audit | Review cycle, audit notes, change logs, corrective actions |
That is the core point. Synthetic-content governance is a lifecycle discipline. If you reduce it to "we added a watermark," you missed most of the problem.
Provenance vs Watermarking vs Detection
These terms get blurred constantly. That creates bad design choices. Provenance is about the origin and handling history of content. Watermarking is a form of labeling or marking. Detection is the attempt to identify synthetic content after the fact. They are related, but they are not interchangeable.
| Technique | Purpose | Strengths | Limits |
|---|---|---|---|
| Provenance | Track source and transformation history | Strong basis for trust, traceability, and governance records | Depends on system adoption and integrity of the provenance chain |
| Watermarking / labeling | Signal that content is synthetic or AI-generated | Supports transparency and user awareness | Can be removed, bypassed, or inconsistently applied; not a complete control set |
| Detection | Identify likely synthetic content | Useful when provenance or labels are absent | Probabilistic, error-prone, and weak as a sole decision basis |
NIST's value here is that it stops you from treating one method as the answer. The report is explicit that organizations should think in combinations of methods and practices rather than assume any single technique solves the synthetic-content problem. The official PDF makes that clear in its scope and method discussion.
Common failure pattern: teams buy a detection tool or add a watermark, then declare the issue solved. NIST's framing points the other way: synthetic-content transparency needs layered controls and ongoing maintenance.
Governance Model for Synthetic Content
The technical discussion only becomes useful when converted into ownership. Synthetic-content governance needs a policy, a labeling workflow, a review and exception process, customer-facing communication, incident escalation, and supplier governance. Otherwise the organization ends up arguing over every edge case in real time.
A workable governance model has five parts. First, define what synthetic content means inside your business and which product flows are in scope. Second, define when visible labels, metadata, or other signals are required. Third, define who can approve exceptions. Fourth, define how suspected misuse or impersonation is escalated. Fifth, define how third-party tools and model providers are assessed and monitored. That structure is more important than whatever synthetic-content marketing language the vendor used in the sales deck.
This is also where NIST AI 100-4 becomes commercially useful for SMEs. It gives you enough structure to design a synthetic-content control baseline without pretending you can solve deepfakes through one tool purchase.
NIST AI 100-4 vs China Labeling Rules vs EU Transparency Logic
NIST AI 100-4 is not law. China's 2025 labeling measures are law. The EU's transparency and labeling trajectory sits inside the AI Act and the Commission's related work on transparent AI systems and AI-generated content labeling. These layers are not equivalent, but they are starting to converge on the same operational question: how should synthetic content be identified, handled, and communicated?
| Dimension | NIST AI 100-4 | China 2025 labeling rules | EU transparency logic |
|---|---|---|---|
| Nature | Technical-governance reference | Binding regulatory measures | Binding transparency obligations plus developing code/guidance support |
| Main emphasis | Provenance, labeling, detection, testing, maintenance | Explicit and implicit labeling of generated/synthetic content | Transparency for certain AI systems and AI-generated content contexts |
| Primary use | Designing controls and workflows | Meeting service-provider and platform obligations in China | Supporting compliance with EU transparency obligations |
For China, the official 2025 notice states that the measures define explicit and implicit labeling, specify how providers must add visible labels in different media types, and require metadata-based labeling in file data. See the official CAC notice. For the EU side, the Commission says the Code of Practice on marking and labelling of AI-generated content is intended to support compliance with AI Act transparency obligations related to marking and labelling AI-generated content. See the Commission page.
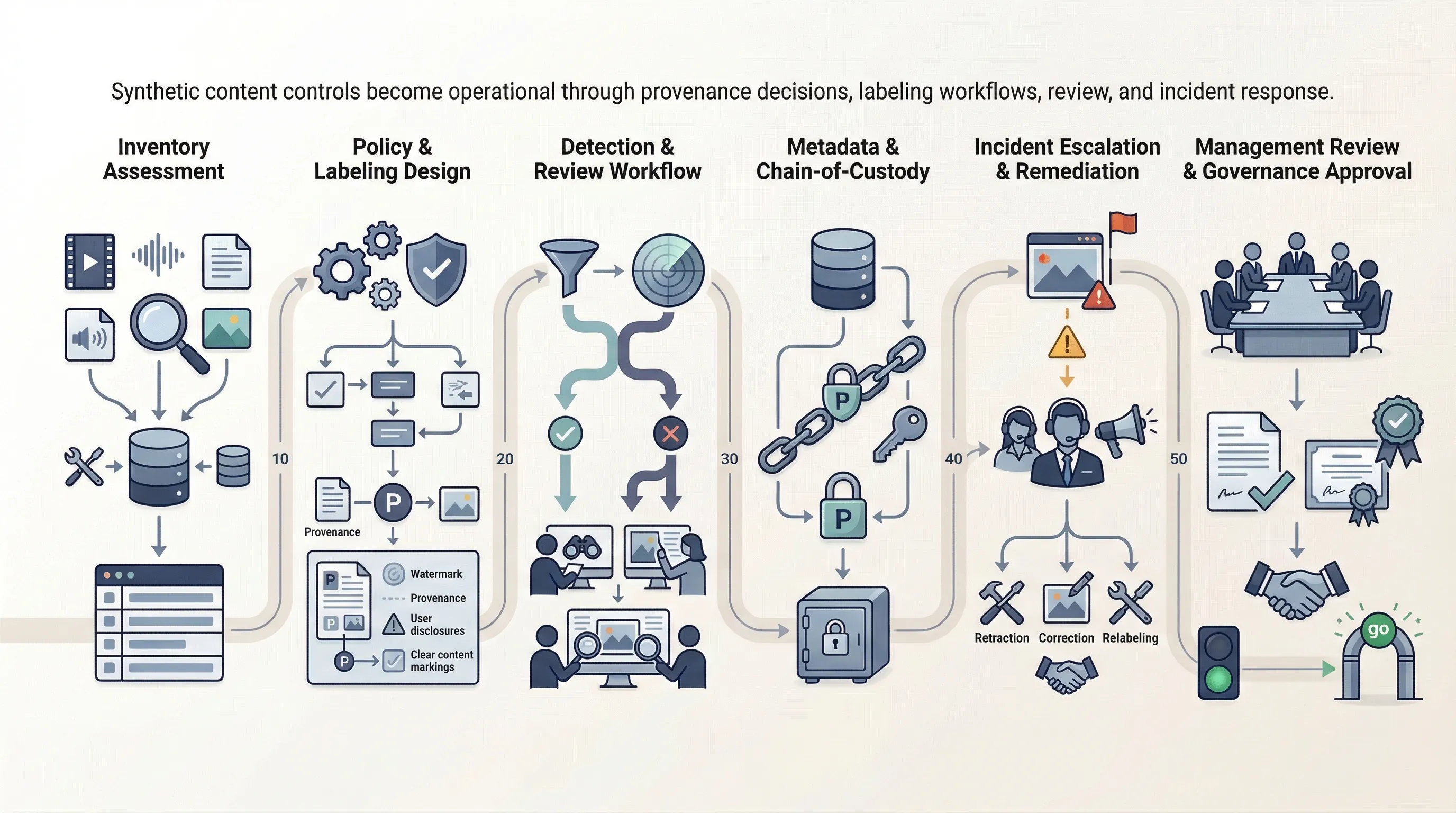
Minimum Controls for SMEs Using Generative Media
Most SMEs do not need a giant synthetic-media lab. They do need a minimum control set. If that baseline does not exist, the organization is exposed operationally whether or not it talks about AI safety in public.
| Minimum control | Why it matters | Evidence |
|---|---|---|
| Approved use-case list | Prevents ad hoc synthetic-media use from spreading without oversight | Use-case register, approval note, owner list |
| Labeling rules | Reduces ambiguity about when and how synthetic content is disclosed | Policy, UI examples, metadata settings, review checklist |
| Provenance retention | Supports traceability and incident handling | Metadata rules, file retention settings, audit trail |
| Human review thresholds | Creates control over higher-risk outputs and edge cases | Review SOP, escalation matrix, approval log |
| Detection escalation | Allows response when unlabeled or suspicious content appears | Detection workflow, incident ticket, response playbook |
| Customer-facing disclosures | Improves trust and reduces dispute risk | Terms, user notices, help center language, support scripts |
That baseline is enough to move an SME from vague awareness to a defensible operating posture.
60-Day Synthetic Content Control Sprint
You do not need a year-long synthetic-content program to get control. You need a short sprint that creates ownership, workflow, and evidence.
- Weeks 1-2: inventory every synthetic-content use case, tool, media flow, and external provider dependency.
- Weeks 3-4: define labeling policy, provenance rules, exception handling, and incident triggers.
- Weeks 5-6: test detection and review workflows, validate metadata retention, and finalize management review of the baseline.
If you cannot do that in 60 days, the blocker is usually not technology. It is ownership. No one owns the synthetic-content workflow, so every issue gets bounced between product, legal, marketing, and security.
Need the templates, not just the concepts? NIST AI 100-4 becomes useful when it is translated into policies, decision trees, workflows, and evidence. That is what AI Controls Professional is built to support.
Compare AI Controls Starter and AI Controls Professional.