The Misconception: Prompt Injection Is "Just" an LLM Problem
Many security teams still frame prompt injection as a model-output integrity issue only. That framing is incomplete in agentic systems. The problem is not merely that the model says something wrong. The bigger problem is that the system may act on the wrong thing, persist the wrong thing, or alter something it should not have touched.
OpenClaw is useful here because it forces a narrower and more realistic view. It does not prove that prompt injection never touches the model. MITRE's OpenClaw investigation explicitly says recurring techniques included direct and indirect LLM prompt injection. What it does show is that in agentic systems, the effective blast radius often extends beyond the model layer into tools, configuration, and operational state. See the MITRE investigation report.
Official source links: MITRE ATLAS OpenClaw Investigation · CTID OpenClaw article · ISO/IEC 42001 official page · ISO 42001 explained · CWE-1427 prompt injection
What OpenClaw Changes About the Threat Surface
MITRE's source language is the key anchor here. The OpenClaw investigation says the analysis observed recurring techniques including direct and indirect LLM prompt injection, AI agent tool invocation, and modifying an agentic configuration. The CTID article adds a useful operating fact: OpenClaw is unique because it can independently make decisions, take actions, and complete tasks without continuous human oversight. Those two points together are what make the threat surface different. See the CTID article.
| Attack surface element | Why it matters | Example consequence |
|---|---|---|
| Model interaction | Unsafe or manipulated instructions can alter system behavior at inference time | Bad output, unsafe decision logic, hidden instruction following |
| Memory / context persistence | Poisoned or unsafe state can persist across steps or sessions | Repeated misuse, contaminated future actions, misleading context |
| Tool invocation | Agent actions can interact with external systems, not just produce text | Unauthorized API calls, unsafe retrieval, data exfiltration, action execution |
| Configuration / policy state | If configuration is mutable, attackers can influence future behavior | Policy drift, unsafe defaults, widened permissions |
| External environment / downstream actions | The system may affect files, services, credentials, or business processes | Operational impact, customer-facing harm, data exposure |
This is the core distinction. Once an agent can call tools, retain memory, modify configuration, or trigger downstream actions, the security problem is no longer just "bad answer quality." It becomes a system-behavior and incident-response problem.
When Prompt Injection Becomes an Incident
This is where most teams still get sloppy. Not every prompt injection finding is an incident. Some are test findings. Some are near misses. Some are contained events. Some are actual incidents because unsafe behavior reached tools, data, configuration, or external actions.
| Scenario | Classification | Typical response |
|---|---|---|
| Unsafe prompt discovered in testing with no operational effect | Test finding | Document, triage, assign corrective action |
| Injection attempt blocked before tool execution or state change | Near miss / contained event | Preserve evidence, review gaps, improve controls |
| Unauthorized tool use attempted or completed | Incident | Contain access, preserve logs, escalate immediately |
| Persistent harmful context or memory introduced | Incident or significant event | Reset state, capture snapshots, assess downstream spread |
| Configuration or policy state modified | Incident | Rollback, isolate system, validate configuration integrity |
| Sensitive data exposed or downstream business process affected | Incident | Run incident response, impact assessment, corrective action, management review |
The operational rule should be simple: the moment prompt injection affects authority, persistence, or business impact, it stops being a model-quality issue and becomes an incident-management issue.
Common failure pattern: teams respond as if the issue was just a bad model answer, when the real problem is unauthorized or unsafe system behavior downstream of the model.
How ISO 42001 Incident Response Controls Apply
ISO 42001 does not name OpenClaw or prompt injection. That is not the point. ISO's public explanation says ISO/IEC 42001 is the international standard for AI management systems and helps organizations manage risks related to AI while supporting innovation, trust, and accountability. ISO also says the standard helps organizations govern AI use, manage risks, support compliance, and build trust in AI-driven processes. That gives you the management-system mechanics you need when the attack pattern is new but the response still needs structure. See ISO 42001 explained.
| ISO 42001 implementation theme | How it applies to OpenClaw-style incidents | Example evidence |
|---|---|---|
| Roles and responsibilities | Clarifies who triages, who contains, who approves rollback, and who reports | RACI, escalation matrix, incident owner log |
| Documented information | Ensures the incident trail is recorded and reviewable | Incident ticket, evidence log, decision record |
| Operational control | Supports emergency restrictions, rollback, and temporary hardening | Containment action log, access change note, freeze order |
| Nonconformity and corrective action | Provides structure for root cause, remediation, and recurrence prevention | Root-cause note, corrective action plan, closure evidence |
| Risk treatment updates | Requires the risk picture to change after the incident | Updated risk register, revised treatment plan |
| Review and improvement | Forces leadership review and system-level improvement | Management review minutes, post-incident lessons learned |
The value of ISO 42001 here is procedural discipline. It helps teams respond systematically even when the underlying agentic attack pattern is new.
Containment: Memory, Tools, Configuration, Environment
A good containment model does not assume one choke point. It treats the model, memory, tools, configuration, and environment as separate but related control surfaces.
| Layer | Immediate containment action | Evidence to preserve |
|---|---|---|
| Memory / context | Freeze or reset unsafe state; isolate session or memory store where possible | Memory snapshot, context history, timestamps |
| Tools | Disable tool calls, revoke permissions, restrict high-risk connectors | Tool invocation logs, authorization events, API call trail |
| Configuration | Rollback or lock configuration and approval paths | Before/after config state, approval records, change logs |
| Environment / downstream impact | Contain affected services, credentials, or business processes | Side-effect logs, service actions, process-impact records |
The right answer is often not "change the prompt." It is "reduce tool authority, reset unsafe state, restore configuration integrity, and stop downstream damage."
Evidence Preservation and Forensics
This is where weak programs fail. Without evidence discipline, teams cannot tell the difference between malicious injection, system misconfiguration, unsafe tool design, operator error, or provider-side issues. For agentic incidents, preserve more than the prompt transcript.
- Prompt and instruction chain
- Model output sequence
- Memory state or retained context snapshot
- Tool invocation logs
- API call records
- Configuration and policy state
- User or session metadata
- External side-effect logs
- Approvals or exception records where relevant
CWE-1427 is also useful supporting context because MITRE explicitly recognizes prompt injection as a software/system weakness category and notes that inputs can cause unintended behavior such as invoking unexpected agents or API calls. See CWE-1427.
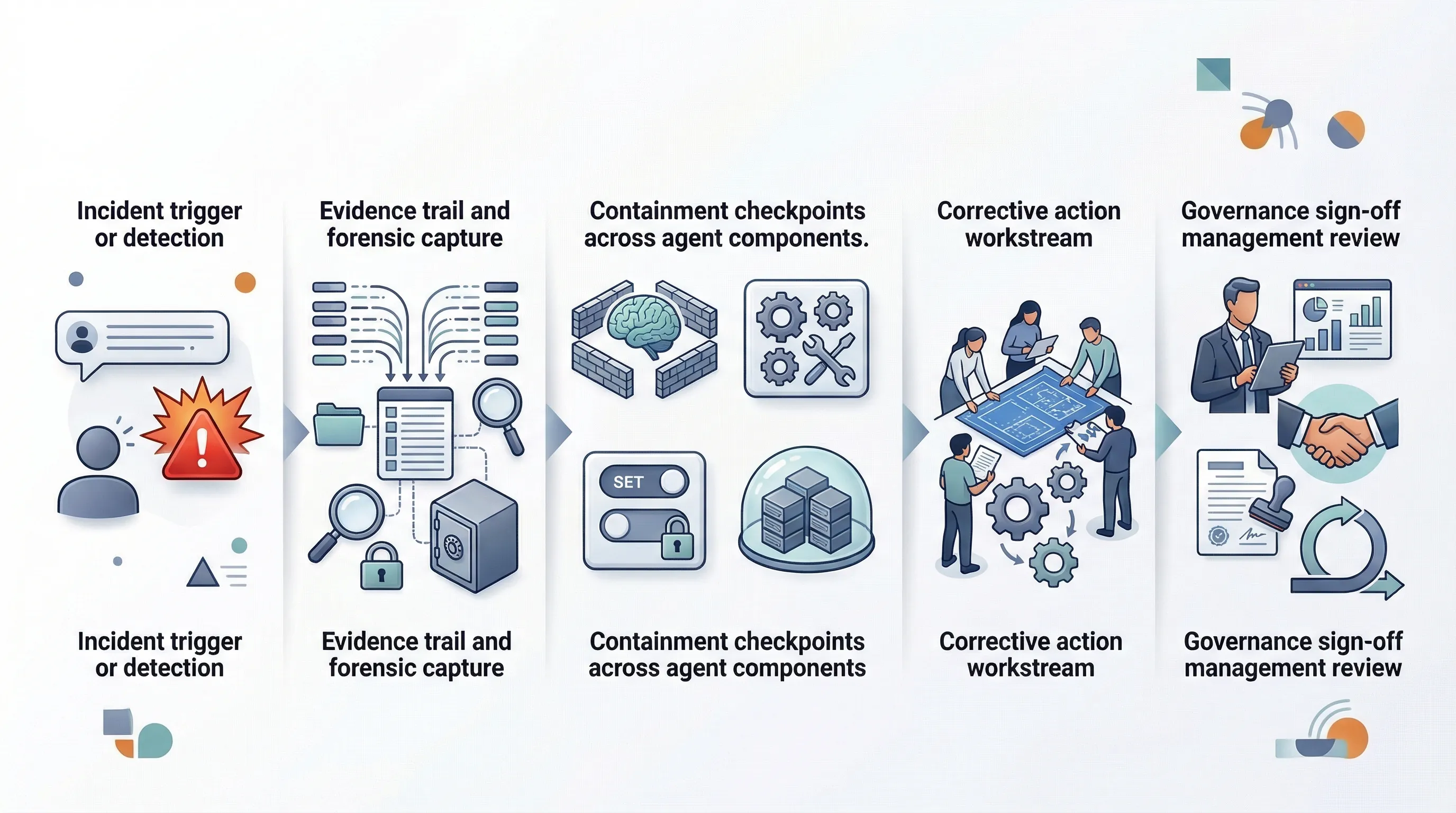
Corrective Action: What Has to Change After the Incident
The right corrective action is often not "rewrite the system prompt." OpenClaw-style incidents may require changes to tool authority, memory design, configuration control, logging, or ownership. This is the part most teams under-invest in because it is easier to patch the visible prompt than redesign the unsafe operating conditions around it.
| Failure pattern | Corrective action | Owner |
|---|---|---|
| Prompt or instruction override succeeded | Harden instruction handling, add validation or policy layers, improve testing | Product + AI engineering |
| Tool authority too broad | Reduce permissions, segment tools, add approval gates | Engineering + security |
| Unsafe memory persistence | Redesign memory scope, retention, or reset behavior | AI engineering |
| Configuration was mutable or weakly controlled | Tighten approval controls, rollback discipline, and configuration integrity checks | Platform owner + security |
| Poor evidence and visibility | Improve logging, evidence preservation, and escalation workflow | Security + governance |
| Ownership confusion slowed response | Clarify incident roles, approvals, and review cadence | Governance owner |
45-Day Agentic Incident Response Sprint
You do not need a giant forensic program. You need a short sprint that turns this attack pattern into a controlled response workflow.
- Week 1: identify all agentic systems with tools, memory, or external actions and define incident-classification triggers.
- Week 2: define evidence requirements, logging expectations, and response owners.
- Week 3: build containment playbooks for memory, tools, and configuration.
- Week 4: test prompt-injection and tool-misuse scenarios.
- Weeks 5-6: review lessons learned, refine corrective actions, and update controls and documentation.
The blocker is usually not technical impossibility. It is organizational ambiguity. No one owns the intersection of model behavior, tooling, memory, and incident response.
Need the playbooks, not just the concepts? OpenClaw-style incidents become manageable when ownership, evidence, containment, and corrective action are already structured. That is where the AI Controls Toolkit (ACT) supports operational governance.
Run the free readiness assessment or compare AI Controls Starter and AI Controls Professional.