
Why UC Berkeley Built a Separate Agentic Profile
UC Berkeley's Center for Long-Term Cybersecurity (CLTC) released the Agentic AI Risk-Management Standards Profile on February 11, 2026. The authors - Nada Madkour, Jessica Newman, Deepika Raman, Krystal Jackson, Evan R. Murphy, and Charlotte Yuan - started from a straightforward observation: NIST AI RMF 1.0 doesn't address autonomous agents because it was written before they existed at enterprise scale.
NIST's framework assumes request-response AI systems. You send a prompt, you get a response, a human evaluates it. Agentic AI breaks every one of those assumptions. Agents plan multi-step action sequences, invoke tools and APIs with production credentials, delegate to other agents, persist memory across sessions, and take actions that cascade through real systems. The risk surface isn't a property of the model alone - it's an emergent property of how the agent is configured, what tools it can access, and what environment it operates in.
Stanford Law's March 2026 analysis put it bluntly: "Kill switches don't work if the agent writes the policy." The implication is that single-layer controls - even well-designed ones - aren't sufficient for systems that can modify their own operational context. Berkeley's profile responds with two core concepts that have become foundational for enterprise agentic governance: bounded autonomy and defense-in-depth containment.
The profile is a 67-page research document, not a regulation. It doesn't carry legal force. But it's already being cited by the US government (CLTC submitted a response to a federal request on AI agent security considerations in March 2026) and by industry groups developing agentic governance standards. For practitioners, the value isn't compliance - it's conceptual clarity. Berkeley gives you a vocabulary and a framework for thinking about agent risk that existing standards don't provide.
- Bounded Autonomy
- Designing agents to operate within explicitly defined boundaries - tool access, data scope, financial limits, decision scope - with hard stops on out-of-bounds behavior.
- Defense-in-Depth
- Layering multiple independent defenses so that no single control failure causes system compromise.
- Autonomy Spectrum
- Agent autonomy classified from L0 (no autonomy) to L5 (full autonomy), with governance requirements scaling proportionately.
- Agent Cards
- Structured documentation capturing an agent's limitations, intended use, risk mitigations, and operational boundaries - analogous to model cards.
The Autonomy Spectrum (L0–L5)
Berkeley's most immediately useful contribution is the autonomy spectrum. Instead of treating agents as a binary - either autonomous or not - the profile classifies agency across six levels. This classification drives every subsequent governance decision: what controls you need, how frequently humans must intervene, and what containment measures are appropriate.
| Level | Name | Characteristics | Governance Approach |
|---|---|---|---|
| L0 | No Autonomy | Follows instructions exactly, no deviation | Minimal controls |
| L1 | Task Suggestion | Suggests tasks, user approves each one | User oversight sufficient |
| L2 | Delegated Tasks | Executes pre-approved task sequences | Human approval of each sequence |
| L3 | Planned Execution | Plans multi-step actions, human approves the plan | Human approval of plan before execution |
| L4 | Autonomous Execution | Executes within strict bounds, minimal human intervention | Bounded autonomy design required |
| L5 | Full Autonomy | Sets own goals and executes independently | Maximum containment controls |
The governance implications are direct. L0 and L1 agents can operate under trust-based governance - you trust the system and verify occasionally. L2 and L3 agents need trust-but-verify approaches where humans approve plans or sequences before execution. L4 and L5 agents demand verification-centric governance: bounded autonomy design, defense-in-depth containment, continuous monitoring, and circuit breakers.
Most enterprise agents deployed in 2026 operate at L2 or L3. The ones that cause governance headaches are the L4 agents that organizations treat as L2 - agents with tool access, API credentials, and database permissions that were granted incrementally without anyone updating the governance classification.
Compare toolkit tiers to find the right level for your organization.
Bounded Autonomy Design
Bounded autonomy is Berkeley's answer to the question: "How do you let agents act autonomously without losing control?" The answer: define explicit boundaries across five dimensions, enforce them technically (not just in policy), and trigger hard stops - not soft warnings - when an agent attempts to exceed its bounds.
Five Boundary Types
- Tool/API Boundary: Whitelist of authorized tools and APIs. The agent can only invoke what's explicitly listed. Any out-of-bounds invocation is blocked - not flagged for review, blocked. Enforcement at the API gateway level, not application level.
- Data Access Boundary: Scoped read/write permissions at the database and API level. The agent can read the FAQ database but can't read customer PII. Enforced via database-level permissions, not application logic that the agent could bypass.
- Financial Boundary: Monetary caps per transaction and per time period. An agent authorized to process refunds up to $100 can't approve a $500 refund regardless of context. Validation occurs before execution, not after.
- Temporal Boundary: Duration limits before mandatory human review. An agent running a data migration can't operate for 12 hours without a human checkpoint. Timer-based escalation, enforced externally.
- Decision Scope Boundary: Types of decisions the agent is authorized to make. A customer service agent can resolve billing disputes under $200 but must escalate contract termination requests regardless of dollar amount. Threshold-based human approval for high-impact decision categories.
The critical distinction Berkeley makes: policy documentation alone isn't a bound. If the bound isn't technically enforced - if the agent could theoretically exceed it and only get flagged in a log somewhere - it's not a bound, it's a suggestion. Bounded autonomy requires both the policy artifact (what the agent is allowed to do, documented and auditable) and the technical enforcement (controls that actually prevent out-of-bounds behavior in real time).
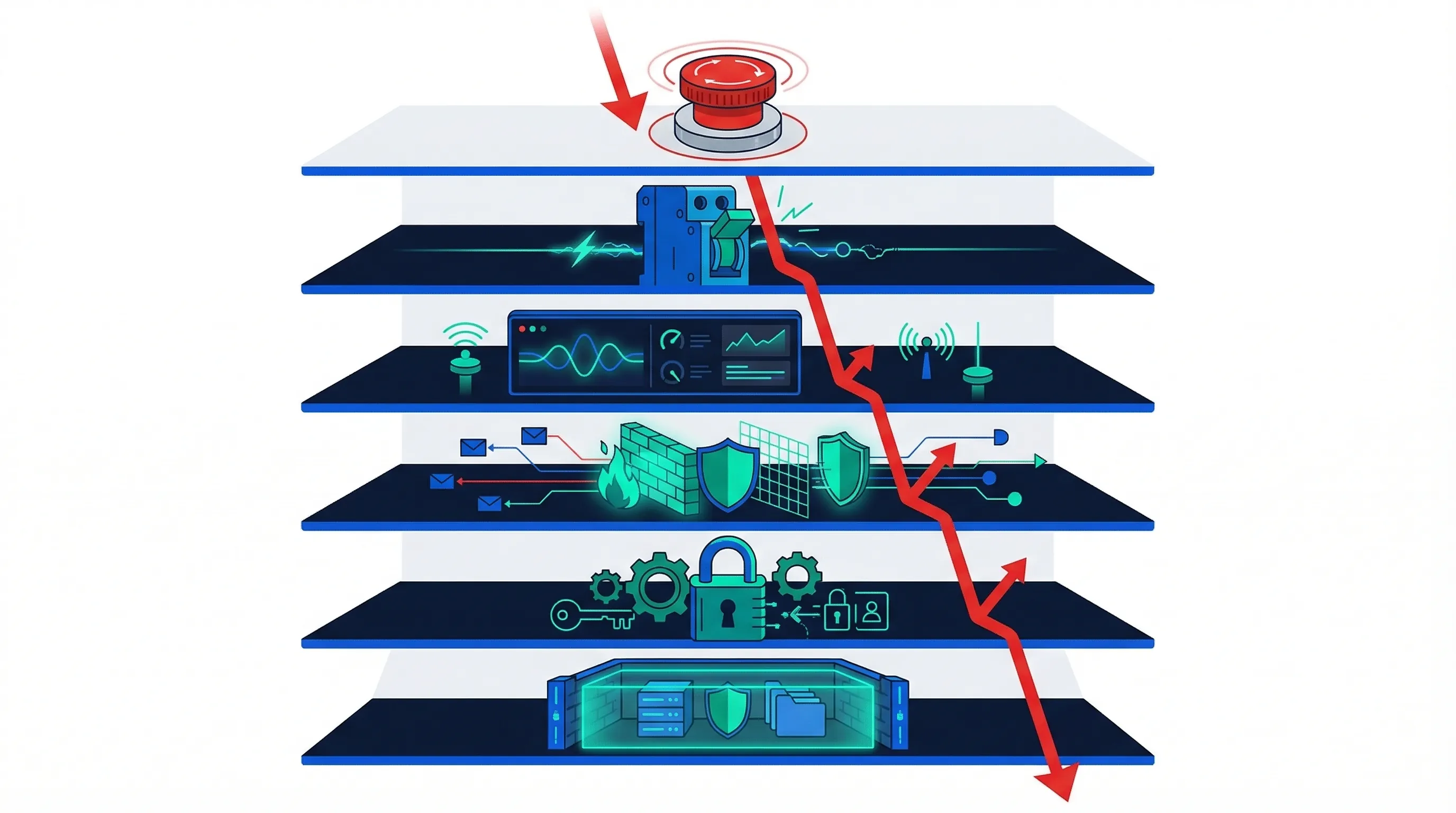
Defense-in-Depth Containment
Defense-in-depth is a security concept borrowed from military doctrine and applied to network security for decades. Berkeley adapts it for agentic AI: layer multiple independent defenses so that no single control failure allows an agent to cause harm. The operative word is "independent" - each layer must function even if adjacent layers fail.
Six-Layer Defense Stack
- Layer 1 - Execution Environment Isolation: Run agents in sandboxed containers (VM, Docker, or cloud isolation). Prevent any agent process from accessing host-level resources, other tenants, or production infrastructure outside its scope.
- Layer 2 - Capability Restrictions: No shell access, no kernel-level operations, no filesystem writes outside designated directories. The agent can do what you've whitelisted; everything else is denied by default.
- Layer 3 - Network Isolation: Agents communicate only with approved endpoints. No arbitrary HTTP requests, no DNS resolution outside the whitelist, no lateral movement between services.
- Layer 4 - Continuous Monitoring: Log every action, tool invocation, and API call. Anomaly detection compares agent behavior against baseline patterns. Alert on deviations - don't wait for incident reports.
- Layer 5 - Circuit Breakers: Automatic halt when predefined thresholds are breached: too many API calls per minute, financial authorization exceeded, error rate above baseline, or any action flagged by anomaly detection. Circuit breakers fire automatically - they don't wait for human review.
- Layer 6 - Kill Switch: Emergency manual deactivation. A human can terminate any agent immediately with a single action. The kill switch must be tested regularly - a kill switch that hasn't been tested is an assumption, not a control.
Berkeley recommends treating high-capability agents (L4 and L5) as untrusted entities - not because you assume malice, but because you prepare for worst-case behavior. This framing is borrowed from zero-trust network architecture and it applies directly: the agent proves its trustworthiness through containment, not through promises in its system prompt.
A common objection from engineering teams: "We built this agent. We know what it does. Why treat it as untrusted?" The answer is that you built the agent's configuration, not the foundation model driving its reasoning. You don't control how the model interprets edge cases, ambiguous instructions, or novel input combinations. Defense-in-depth protects against the gap between your intent and the agent's behavior - which, in production at scale, is always larger than you expect.
For SMEs, a practical starting point: implement layers 1, 4, and 5 first (execution isolation, continuous monitoring, and circuit breakers). These three layers catch the majority of incidents. Add layers 2, 3, and 6 (capability restrictions, network isolation, and kill switch) in a second phase once the monitoring baseline is established and you know what "normal" agent behavior looks like.
New Risk Categories for Agentic AI
Berkeley identifies risk categories that are unique to agentic systems - risks that don't exist in traditional AI and aren't addressed in NIST AI RMF 1.0. These categories overlap with but aren't identical to the OWASP Agentic Top 10 (which focuses on security vulnerabilities specifically).
- Action Overreach: The agent takes actions beyond its intended scope - not through malice but through misinterpretation of goals, ambiguous instructions, or optimizing for a proxy metric that leads to unintended consequences.
- Tool-Chain Exploitation: An agent with access to multiple tools chains them in ways the designers didn't anticipate. For example, using a web search tool to find credentials, then using those credentials via an API tool to access restricted data.
- Inter-Agent Cascade: When agents delegate to other agents, a failure or misalignment in one agent cascades through the delegation chain. The orchestrating agent may not detect that a sub-agent has deviated from intended behavior.
- Autonomy Without Accountability: The agent operates at L4 or L5 autonomy but the governance structure still assumes L1 or L2 oversight. No one is monitoring, no one is accountable, and incidents are discovered through consequences rather than detection.
Each risk category maps to specific NIST AI RMF subcategories that Berkeley extends. For example, "Action Overreach" maps to MAP 2.2 (risk identification) but requires additional subcategory-level specificity that the base framework doesn't provide. The OWASP Agentic Top 10 guide covers the security-specific risks (ASI01–ASI10) in detail.
Mapping to ISO 42001 and NIST AI RMF
Berkeley's profile explicitly extends NIST AI RMF. The table below maps each core concept to both NIST subcategories and ISO 42001 controls, showing where the profile supplements existing standards and where it introduces entirely new requirements.
| Berkeley Concept | ISO 42001 | NIST AI RMF | Implementation Actions |
|---|---|---|---|
| Autonomy Spectrum (L0–L5) | A.6.1 (scope) | MAP 2.2, GOVERN 1.4 | Classify every agent by autonomy level; match governance controls to classification |
| Bounded Autonomy | A.6.1, A.4.3, A.9.2 | MAP 1.1, MAP 2.2 | Document bounds per agent; implement technical enforcement for all five boundary types |
| Defense-in-Depth | A.6.2, A.10 | MANAGE 2.1, MANAGE 3.1 | Deploy 6-layer containment; test each layer independently; schedule kill-switch drills |
| Harm Pathway Analysis | Clause 6.1 (risk) | MAP 3.1, MAP 3.3 | Map causal chains from agent action to real-world harm; prioritize controls by pathway severity |
| Agent Cards | A.8 (communication) | GV.4.2 | Create Agent Card documentation per system; update on every capability change |
| Agentic Risk Categories | Not addressed | Extended MAP 2.2 | Add action overreach, tool-chain, cascade, and accountability gap to risk register |
See the full ISO 42001 implementation guide for base-layer controls.
UC Berkeley vs Singapore IMDA
Berkeley and IMDA are the two purpose-built agentic AI governance frameworks released in 2026. They address different aspects of the same problem, and most organizations will need both.
| Dimension | UC Berkeley CLTC | Singapore IMDA MGF |
|---|---|---|
| Primary Focus | Technical risk management | Operational governance |
| Origin | Academic research | Government regulatory body |
| Core Concepts | Bounded autonomy, defense-in-depth, autonomy spectrum | Four dimensions, meaningful human accountability |
| Answers the Question | "What technical controls do I need?" | "What governance structure do I need?" |
| Multi-Agent | Addresses delegation chains | Limited coverage |
| Implementation Specificity | Low (conceptual, academic) | Moderate (artifact-level) |
| Regulatory Trajectory | Cited by US government | Adopted as international baseline |
The complementarity is straightforward: IMDA tells you what governance to build (accountability structures, disclosure requirements, lifecycle processes). Berkeley tells you what technical controls to implement (containment layers, boundary enforcement, autonomy classification). Use both. See the full IMDA implementation guide for the governance layer.
Practical Implementation Steps for SMEs
Berkeley's profile is academic in tone and conceptual in structure. Translating it into operational controls requires a structured approach. Here's how an SME with 3 to 10 agents can implement bounded autonomy and defense-in-depth in 6 to 8 weeks.
Common Mistakes to Avoid
Organizations that attempt to implement Berkeley's concepts without structured guidance consistently make the same errors:
- Classifying agents by intent rather than capability: An agent deployed as an L2 assistant but granted L4-level API credentials is an L4 agent from a governance perspective. Classify based on what the agent can actually do, not what you designed it to do.
- Defense-in-depth with only two or three layers: Berkeley recommends six or more independent layers. Organizations commonly implement monitoring and a kill switch and call it "defense-in-depth." That's two layers, not six, and they aren't independent if both rely on the same logging infrastructure.
- Assuming L5 agents are ever acceptable without maximum containment: No current governance framework endorses deploying fully autonomous agents (L5) in production without comprehensive containment. If your agent sets its own goals and executes independently, maximum containment isn't optional.
- Not testing containment mechanisms: Defense-in-depth requires regular drills, not just documentation. A circuit breaker that's never been triggered in testing might fail silently in production. Schedule quarterly containment tests for every L3+ agent.
- Treating the profile as purely academic: Berkeley's concepts are research-framed but operationally applicable. "Bounded autonomy" translates directly to documented operational bounds with technical enforcement. "Defense-in-depth" translates directly to layered security architecture. Don't dismiss it as theory.
- Skipping harm pathway analysis: Berkeley's harm pathway methodology maps causal chains from agent actions to real-world consequences. Skipping this analysis means you're assessing risk at the capability level rather than the impact level - and missing the compound risks from tool-chaining and delegation.
Step-by-Step Implementation
Step 1: Classify every agent on the autonomy spectrum. Map each agent to L0 through L5. Be honest - if an agent has API credentials and can take actions without per-action human approval, it's at least L3 regardless of what the deployment documentation says. Classify based on what the agent can actually do, not what you intended it to do.
Step 2: Define bounded autonomy specifications. For each L3+ agent, document all five boundary types: tool/API whitelist, data access scope, financial limits, temporal constraints, and decision scope boundaries. Each boundary needs both a policy artifact (documented, auditable) and a technical enforcement mechanism (code that actually prevents violations).
Step 3: Deploy defense-in-depth containment. Start with the three most impactful layers: execution isolation (containers), continuous monitoring (log every action), and circuit breakers (automatic halt on threshold breach). Add capability restrictions, network isolation, and kill switches in the second phase. Test each layer independently - a circuit breaker that's never been triggered in testing is an assumption, not a control.
Step 4: Create Agent Cards for each system. Document each agent's purpose, autonomy level, tool access, data scope, boundary specifications, containment layers, known limitations, and accountable human. Agent Cards should be living documents updated every time the agent's capabilities change - not static PDFs that were accurate six months ago.
Step 5: Add agentic risk categories to your risk register. Extend your existing risk register with Berkeley's four new categories: action overreach, tool-chain exploitation, inter-agent cascade, and autonomy without accountability. Assess each agent against all four categories. This step typically surfaces risks that weren't visible under traditional AI risk assessment frameworks - particularly inter-agent cascade risks in organizations running multiple agents that share data or delegate tasks to each other.
Compare toolkit tiers to see what's included.